Scrapy¶
Scrapy is application framework that allows you to crawl for wider range of applications
Key Components¶
Architecture overview from Scrapy’s official doc has following diagram, which explain flow of data
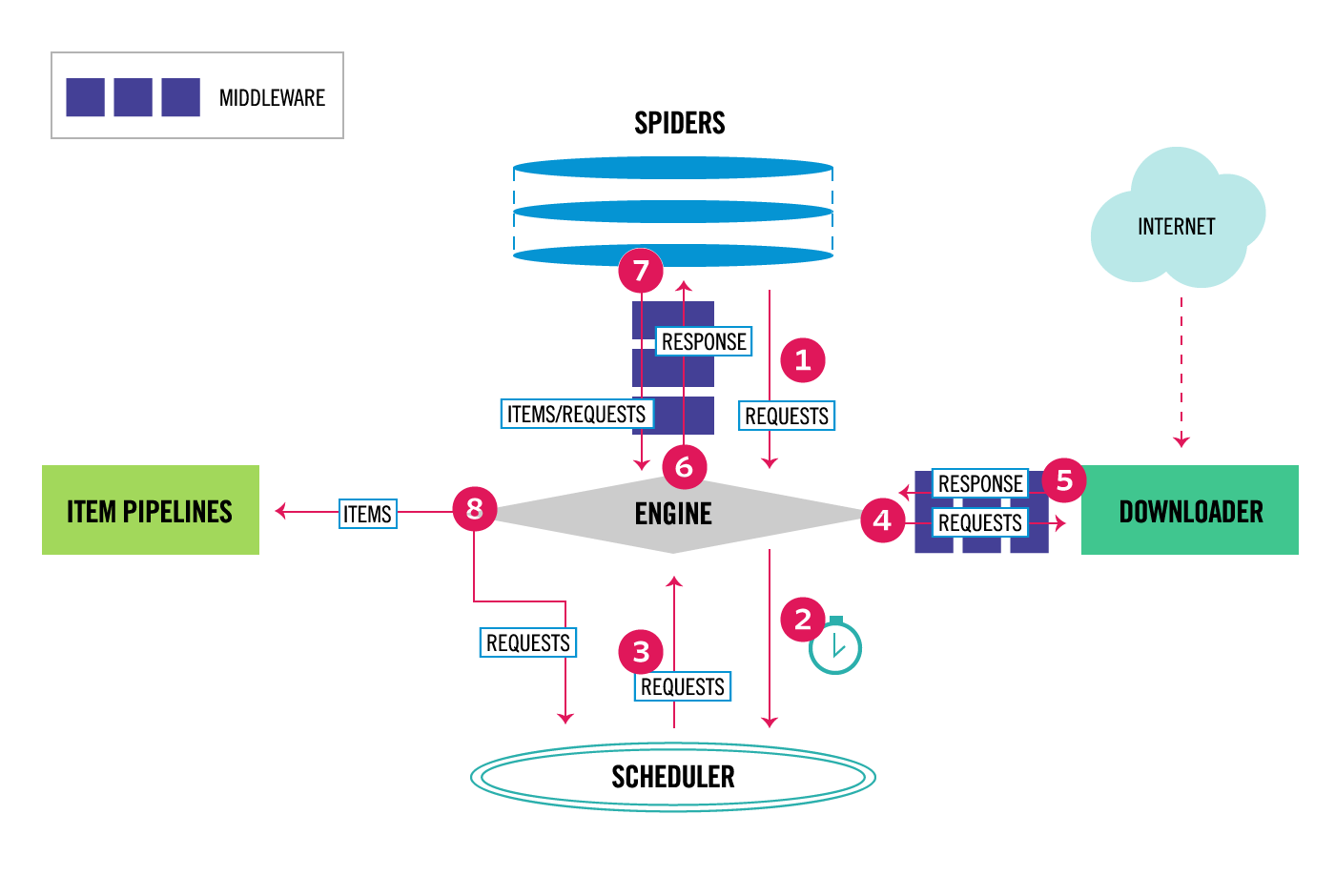
Following explains main components of Scrapy
Scrapy Engine: Co-ordinates all data flow between components
Scheduler: Enqueueing and storage of URLs is the main job of this component. It gets them as Request objects from Engine
Downloader: This is the component that actually does the job of downloading page. This gets feeded back to Spider via Engine by means of Response objects
- Spiders: Custom class written with logic to
Parse Response
Extract Item
- Item Pipeline: Contains logic to process all items once extracted, this include:
Cleansing
Validation
Persistance
Downloader middlewares: Set of hooks that sit between Engine and Downloader.
Spider middlewares: Set of hooks that site between Engine and Spider
Quickstart¶
Create a project using
scrapy startproject tutorial
- Spider class custom contains logic to scrape information from one or more sites. This is generally extended from scrapy.Spider. Following information is also provided:
Initial request
How to follow links on page
How to parse downloaded information
E.g. create quotes_spider.py within spiders directory
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
- Note:
name: Specified name of the spider
start_requests method: Contains seed url from which we expand on
- parse methodThis is handler that gets called when response is downloaded. Contents of html is usually present in TextResponse attribute of response object. This method is also responsible for:
Figuring out which URLs to follow
Extracting item as dictionary
Run the spider using
scrapy crawl quotes
Alternative way to specify seed url
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
Note
You can use response.url to call custom parsing method, this is useful in situation where you want to use single Spider for multiple domains
Shell allows you to learn more and debug, which can be invoked using
scrapy shell 'http://quotes.toscrape.com/page/1/'
Storing scraped data into JSON can be done as follows
scrapy crawl quotes -o quotes.json
Returning records using yield keyword, can be done as follows
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
Note: The above yield is for Item object
We can follow a link using scrapy.Request as follows
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
Shortcut for the above can be done using response.follow as follows
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
You can create custom call for Item and yield that instead of dictionary in Scrapy. E.g.
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
def start_requests(self):
yield scrapy.Request('http://www.example.com/1.html', self.parse)
yield scrapy.Request('http://www.example.com/2.html', self.parse)
yield scrapy.Request('http://www.example.com/3.html', self.parse)
def parse(self, response):
for h3 in response.xpath('//h3').getall():
yield MyItem(title=h3)
for href in response.xpath('//a/@href').getall():
yield scrapy.Request(response.urljoin(href), self.parse)
Generic Spiders¶
Scapy has few generic spiders, which include:
These allow you to avoid writing redundant functionalities, by re-using these classes with your custom logic.
LinkExtractor¶
LinkExtractor allows to extract links from webpages using scrapy.http.Response. They are mixed with Rule to specify what URLs can be allowed along with denied ones aswell.
For example:
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
HTML parsing with bs4¶
bs4 is a popular package used to parse HTML and XML. This can be used in conjunction with Scrapy. lxml is used along with bs4 as a backend.
Find multiple-elements using find_all
moretxt = """
<p>Visit the <a href='http://www.nytimes.com'>New York Times</a></p>
<p>Visit the <a href='http://www.wsj.com'>Wall Street Journal</a></p>
"""
soup = BeautifulSoup(moretxt, 'lxml')
tags = soup.find_all('a')
type(tags)
Finding html element by id using find
div = soup.find(id="articlebody")
Finding html by tag and attirbute
results = soup.findAll("td", {"valign" : "top"})
Reference: More examples on official documents