Driving engagement for B2C Mobile App¶
Introduction¶
A B2C Mobile application was seeking to increase its engagement metrics. Will users engage better with relevant content? this was the hypothesis that needed validation.
Current process involved manually curating of Topics, on which content creation by users happened. Fafadia Tech delivered this projects in 3 calendar months.
Fafadia Tech built a Persona Engine that was deployed and tested in production with substantial daily actives. Along the way we empowered our clients to create their first data pipeline.
Outcome¶
The project didn’t achieve the hard goal of increasing engagement by 30% weekly (Engagement did increase by 15%), however few softer results were achieved
UI tweaks were identified to educate users that suggestions were coming from algorithms
Thinking gears were in motion for Customer’s engineering team
What was discovered was users show higher level of engagement for Trending topics
Key Challenges¶
Some of the challenges that were tackled along the process included:
Dealing with unstructured data. Data had to be transformed to let algorithms do their jobs.
Working with clients on defining soft and hard success metrics.
Building scalable data pipeline that processed data daily
Problem Definition¶
Given a user U and an action A, {where A can be an action E.g. Comment, Like and Write}
We would want to implement a model { recommendation algorithm} RECCO which can be defined as
RECCO(U, A, M) -> T
Where U is a User, A is a vector of actions {i.e. the context}, M is model which we used to generate T. T is set of ranked Topics
Domain Specific Extension¶
Current implementation can be applied to different settings. This can be achieved by abstracting User and Action, we can generate suggestions
By looking at Item to Item interactions
By looking at User to User similarity and aggregating suggestions scores
Lets say we’re building engine for Mobile News Application setting, a user can interact in one of the following ways
Like/Dislike an Article
Spend time reading article in detail
Expanded on article after searching using keywords
Here suggestion can be generated, by examining User’s session:
Item to Item: Generate similarity score for item-item pairs
User to User: Generate similarity scores for user-user pair and use aggreate score to make news article suggestions
Project Plan¶
Write Scripts to get data from DB/API to say MongoDB
- Implement non NLP methods for Recommendations
Conditional Probability Method {using Frequency Counts}
Set Similarity Metrics Methods
Collaborative Filtering Algorithm: LDA
- Implement NLP Methods
Clustering Methods: We will be using simple K-means algorithm
Taxonomy Based Suggestion: Figure out sub-topics that user has interacted with and suggest siblings
Evaluation of Algorithms/Techniques
API for Integration
Architecture¶
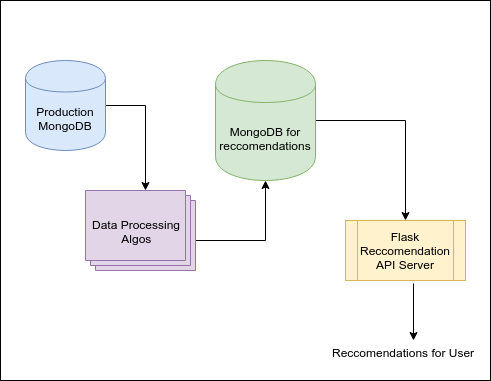
Some of the components used for building Persona Engine included:
Flask: Framework for building APIs
MongoDB: Datastore for storing user generated data and final results
Python: Programming language to implement algorithms
Technical Solution¶
Project was executed in two phases,
Exploratory Data Analysis (EDA)
Implementation and Evaluation
During EDA phase basic statistics were computed, which answered questions like:
On average how many topics a user engages with?
Who is our typical user?
When do they not engage with manually curated list of topics?
What are some interesting topics users engage on during last 30 days?
Is there a tribe that users belong to?
During implementation, following Algorithms were implemented
Graph Based
For this category of recommendation algorithm, we had created a similarity of graph between items {based on cosine distance of their co-occurance vectors}
Suggestions for a user were generated by combining similarity scores. This algorithm emulates “neighbourhood” method.
Alternatively new techniques like item2vec use skip-gram negative sampling for learning vector representation of items. Cosine scores between the vector can be used for computing similarity.
Frequency Based
Pair of items can be samples from the action logs and their Pointwise Mutual Information would be a good proxy of how they are “related”
Content Based
Content based recommendation looks at semantic associations between items. Few techniques that were evaluated includes:
Locality Sensitive Hashing {aka LSH}
Matrix Factorization
Matrix factorization techniques try to predict values of missing entries in a User to Item matrix. Thus it tries to predict how interesting a suggestion would be. Generally this techniques are useful where there is a scale rating {as opposed to binary E.g. Like/Dislikes}. Some of the techniques that were used for this class of Algorithm include:
Singular Vector Decomposition {aka SVD}
Non-negative Matrix Factorization {aka NMF}
Few lessons and tweaks that we performed on the way:
Using time-window to restrict candidate improved runtime of algorithms
Freshness had to be factored in {topics which were recent had their scores boosted}
Faster techniques like LSH Locality Sensitive Hashing was used as opposed to cosine scores
Infrastructure code to server and re-generate scores was built to run every 24 hours
Excellent reference on LSH exists which details inner workings of LSH based engines.
Evaluation¶
- Use of theoretical values:
F1 Scores {Combination of Precision and Recall}
For some algorithms we can use cross-validation scores {i.e. Training Error vs. Testing Error}
- Use of analytics:
A/B Testing