Scikit Learn¶
Introduction¶
- Common Notations in ML
X {collection of feature vector x}
y {collection of labels/target variables}
Theta model parameters
- Types of Machine Learning
- Based on Methods
Supervised vs Un Supervised
Semi-supervised {E.g. Google Photos clustering images based on Faces, then you just have to Tag a single instance per person}
Reinforcement Learning {E.g. AlphaGo - Agents, Environment, Action, Reward and Policy}
- Based on Output
Regression {Continuos}
Classification
Ranking
- Based on requirement for Updates
Batched {Offline}
- Online Algorithms
Receive data continuously {E.g. Ticker Data}
Out-of-core learning: Cannot fit entire dataset in Memory
Bad Data == Gradual Decline
Hence require continuos monitoring and if possible revert to older state of Model
- Few Example of ML Algorithms
- Supervised
kNN
Linear Regression
Logistic Regression
SVM
Decision Trees & Random Forest
Neural Networks
- Unsupervised
k-Means
Hierarchial Clustering Analysis
Expectation Maximization
Principal Component Analysis
Kernel PCA
Locally-Linear Embedding
t-SNE: t-distributed stochastic neighbor embedding
Apriori
Eclat
- Representation of data in scikit learn
All data has to be in form of NumPy matrix or Array
Input data in 2D matrix and size of the matrix: n_samples (number of rows), n_featres (number of columns)
Iris dataset is a classic dataset for machine learning in classification settings
sklearn.datasets has a few datasets that we can use for testing/training
When you have new dataset to study relation amongst attributes it might make sense to use Scatter Plots
dataset.fetch_ → autocomplete will get you list of all dataset available to scikit learn for download
- Basic Principles of Machine Learning
Every algorithm/model in scikit learn is is exposed via Estimator object (Each represented by a class).
Estimator parameter when it is instantiated e.g. model = LinearRegression(normalized=True)
Scikit learn separates model from data
Convention: Capital letters for matrices and lower cases letters for arrays/vectors
model.fit(X, y) used to train our model/algorithm
- Supervised Learning: Classification and Regression
Classification - output is discrete
Regression - output is continous
KNeighboursClassifier -> knn.fit, knn.predict
knn.predict_proba → gives probability distribution over output targets
Putting ? at the end brings up the documentation
SVC - Support Vector Machine Classifier (based on LibSVM)
Different models will produce different predictions
How to choose which model to choose? (This is best answer using Model validation)
RandomForestRegressor → RandomForest model for doing regression tasks
Tip: In iPython if you hit Shift + Tab between round brackets it will show you list of parameters
- Unsupervised Learning: Dimensionality Reduction and Clustering
Find combination of features that will best allow us to classify
Dimensionality Reduction PCA. Maps higher dimensional data in to lower dimensional
Unsupervised don’t have output y in fit e.g. pca.fit(X) (
Challenges of ML¶
- Insufficient Quantity of Training Data
Unreasonable effectiveness of data - basically this research show adding more data to crappy algorithms give comparable results as sophisticated algorithm. So then choice between spending time to collect more data vs. spending time to improve algorithms becomes obvious
Non-representative Training Data - Black Swarn effect
Poor Quality Data
Irrelevant Features
- Overfitting the Training Data
Noisy training dataset tunes model to detect noise as pattern
- Possible solutions to over-fitting
Simplify model selection
Gather more training data
Reduce noise in dataset {E.g. fix data errors, remove outlines}
Constraining model to make it simple and reduce the risk of overfitting is called regularization
The amount of regularization to apply during learning can be controlled by hyperparameter {NOTE: Hyperparameters is parameter of learning and not algorithm itself}
- Underfitting the Data
It occurs when your model is too simple to learn the underlying structure of data.
Signal of when this happens is predictions are inaccurate even on the training examples
- Possible solutions
Selecting a more powerful model
Feeding better features to learning algorithm
Reducing the constrain on model {E.g. reducing the regularization hyperparameter}
Note
Estimator objects implement fit and predict methods.
ML Framework¶
Approaching (Almost) Any Machine Learning Problem by Abhishek Thakur is a good tutorial on building abstract ML framework, as shown below:
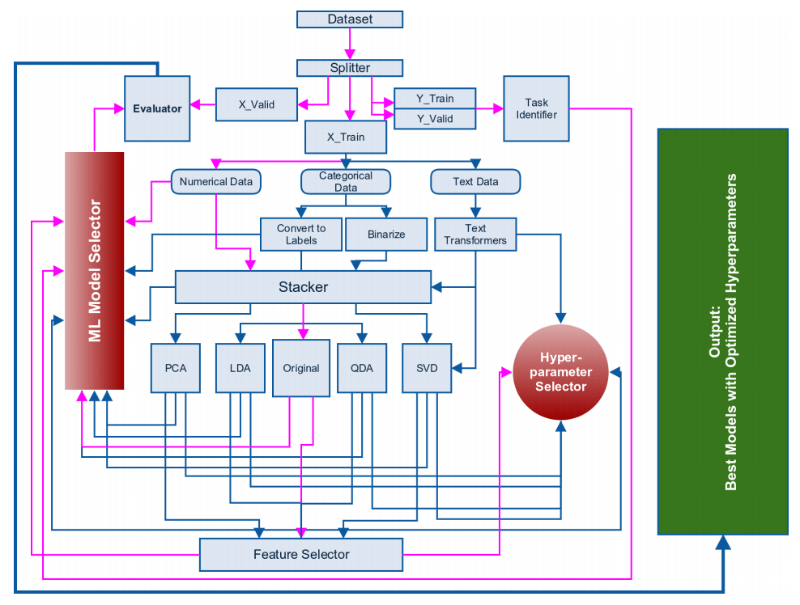
Linear Regression¶
Following is example of linear regression from Scikit’s official documents
>>> import numpy as np
>>> from sklearn.linear_model import LinearRegression
>>> X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
>>> # y = 1 * x_0 + 2 * x_1 + 3
>>> y = np.dot(X, np.array([1, 2])) + 3
>>> reg = LinearRegression().fit(X, y)
>>> reg.score(X, y)
1.0
>>> reg.coef_
array([1., 2.])
>>> reg.intercept_
3.0000...
>>> reg.predict(np.array([[3, 5]]))
array([16.])
Ensemble Method¶
Ensemble techniques allow you to create a strong model from collection of weak models. Following is example in context of text classification
import os
import re
import sys
import json
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.decomposition import TruncatedSVD
from sklearn.metrics import accuracy_score, log_loss, confusion_matrix
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from gensim.models import KeyedVectors
from gensim.test.utils import datapath
print("Loading word2vec")
word2vec = KeyedVectors.load_word2vec_format(datapath("/Users/sidharthshah/Code/machine_learning/news_scout/data/pre_trained_models/word2vec/GoogleNews-vectors-negative300.bin"), binary=True)
stoplist = [word.strip() for word in open("stopwords.txt").readlines()]
DIM = 300
def cleanup_text(snippet):
"""
this method is used to cleanup text
"""
snippet = snippet.lower().strip()
snippet = re.sub(r'[^\w\s]', '', snippet)
snippet = snippet.replace("\n", "")
snippet = " ".join(snippet.split())
return snippet
def embeddings(doc):
"""
this function is used to get additive embedding
on all words in document
"""
stop_word_filter = lambda x: x not in stoplist
vector = [np.zeros(DIM)]
for current in list(set(filter(stop_word_filter, doc.split()))):
if current in word2vec:
vector = np.add(vector , word2vec[current])
else:
vector = np.add(vector, [np.zeros(DIM)])
return vector
def pre_process(directory):
"""
this method is used to pre-process data, it does
1. Reads JSON files
2. Returns Pandas Frame with Text and Label
"""
results = []
MAX_WORDS = 0
for current in os.listdir(directory):
file_to_read = os.path.join(directory, current)
data = json.loads(open(file_to_read).read())
for instance in data:
row = {}
row['title'] = instance['title']
row['blurb'] = instance['blurb']
row['text'] = cleanup_text(instance['title']) + " " + cleanup_text(instance['blurb'])
if MAX_WORDS != 0:
row['text'] = " ".join(row['text'].split()[:min(len(row['text']), MAX_WORDS)])
else:
row['text'] = " ".join(row['text'].split())
row['target'] = file_to_read.split("/")[1].replace(".json", "")
results.append(row)
return pd.DataFrame(results)
def gen_counting_features(dataset):
"""
this is used to generate various counting features
"""
results = []
for _, row in dataset.iterrows():
rec = {}
rec['title_char_len'] = len(row['title'])
rec['title_word_len'] = len(row['title'].split())
rec['title_density'] = rec['title_char_len'] / float(rec['title_word_len'])
rec['blurb_char_len'] = len(row['blurb'])
rec['blurb_word_len'] = len(row['blurb'].split())
rec['blurb_density'] = rec['blurb_char_len'] / float(rec['blurb_word_len'])
results.append(rec)
return pd.DataFrame(results)
def gen_embedding_features(dataset):
results = []
for _, row in dataset.iterrows():
vector = embeddings(row['text']).flatten()
results.append(vector)
return results
train = pre_process("train")
print("Vectorizing")
# select between CountVectorizer or TfidfVectorizer
# vectorizer = CountVectorizer(stop_words='english', min_df=5)
vectorizer = TfidfVectorizer(stop_words='english', min_df=30)
le = LabelEncoder()
svd = TruncatedSVD(n_components=300, n_iter=7, random_state=42)
print("Extracting features")
X_train = svd.fit_transform(vectorizer.fit_transform(train['text']))
# this is how you can stack hand generated features
# X_train_counting_features = gen_counting_features(train)
# X_train = np.hstack((X_train, X_train_counting_features.values))
X_train_embedding_features = gen_embedding_features(train)
X_train = np.hstack((X_train, X_train_embedding_features))
print(X_train.shape)
y_train = le.fit_transform(train['target'])
print("Training model")
rf_clf = RandomForestClassifier(n_estimators=50, oob_score=True, random_state=42)
bnb_clf = BernoulliNB()
svc_clf = SVC(gamma='scale', probability=True)
clf = VotingClassifier(estimators=[('RandomForest', rf_clf), ('BernoulliNB', bnb_clf), ('SVC', svc_clf)], voting='soft')
# altenative classifiers
# clf = BernoulliNB()
# clf = SVC(gamma='scale', probability=True)
scores = cross_val_score(clf, X_train, y_train, cv=5)
print(scores)
clf.fit(X_train, y_train)
print("Completed training model")
test = pre_process("test")
print("Extracting features for test dataset")
# X_test_counting_features = gen_counting_features(test)
# X_test = np.hstack((X_test, X_test_counting_features.values))
X_test = svd.transform(vectorizer.transform(test['text']))
X_test_embedding_features = gen_embedding_features(test)
X_test = np.hstack((X_test, X_test_embedding_features))
y_test = le.transform(test['target'])
print("Testing model")
y_test_predicted = clf.predict(X_test)
y_test_predicted_probab = clf.predict_proba(X_test)
accuracy = accuracy_score(y_test, y_test_predicted)
print(f"Accuracy Score:{accuracy}")
print(metrics.classification_report(y_test, y_test_predicted, target_names=le.classes_))
print(f"Log Loss:{log_loss(y_test, y_test_predicted_probab)}")
for i, label in enumerate(le.classes_):
print(i, label)
print(confusion_matrix(y_test, y_test_predicted))
References: